I have been diagnosing very subtle bug in SQL code which led to unexpected results. It happens under rare circumstances, when you do update with join and you want to increase some number by one. You just write value = value + 1. The thing is, you are willing to increase the value by the number of joined rows. The SQL code kind of expresses your intent. However, what actually happens is, the existing value is read only once. It is updated 3 times, indeed. But with the same value, incremented only by one.
Archive for Solutions
UPDATE with JOIN subtle bug
Category: General programming, Solutions |
Unix tools always work. Even when Windows ones don’t
In the video above, you can see, that we cannot drag and drop a file onto a PowerShell script. Conversely, we can easily do this with bash script having installed Git for Windows.
I needed to perform some trivial conversion within a SQL script, i.e. replace ROLLBACK with COMMIT. I thought I would implement it with PowerShell. I am not going to comment on the implementation itself, even though it turned out to be not that obvious. Then I realized, it would be nice, if I could drag and drop a file in question to apply the conversions on it.
This does not work with default configuration of PowerShell. I did not have time to hack it somewhere in the registry, as I assume it is doable. I switched to old, good bash shell instead.
It’s a pity I couldn’t do that with Windows native scripting technology. It is very interesting, that MinGW port of shell has been so carefully implemented, that even dragging and dropping works in non-native environment.
I recall the book Pragmatic Programmer: From Journeyman To Master. There is a whole subchapter about the power of Unix tools. The conclusion was, that over time we would come across plenty of distinguished file formats and tools to manipulate data stored with them. Some of them may become forgotten and abandoned years later, making it difficult to extract or modify the data. Some may work only on specific platforms.
But standard Unix tools like shell scripting, Perl, AWK will always exist. I should say: not only will they always exist, but also they will thrive and support almost every platform you can imagine. They work on plain text, which is easy to process. I am a strong proponent of before-mentioned technologies and I have successfully used them many times in everyday work. It sounds particularly strange among .NET developers, but this what it looks like. The PowerShell simply did not do the trick for me. Perl did. As it always does.
For the sake of the future reference I am including the actual scripts:
PowerShell script:
Bash script running Perl:
‘Differs only in casing’ class of problems
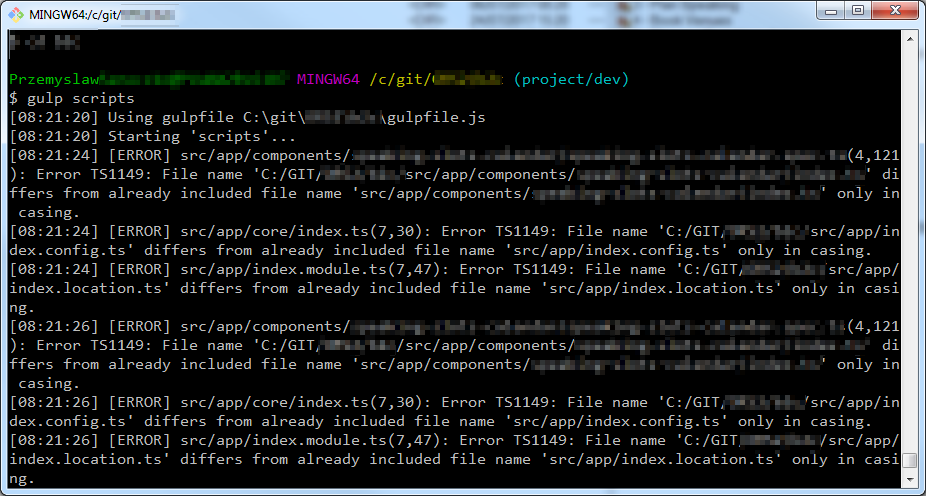
Error message from TypeScript compiler
This one attacked me yesterday by the end of the day. This is a TypeScript project with some instrumentation done with gulp. The command shown attempts to launch TypeScript compiler. The console is standard git bash for Windows. I didn’t realize what was going on there at the first sight. The messages were confusing and mysterious. I made sure I didn’t have any changes in the repository comparing to the HEAD. I opened the folder in Visual Studio Code and everything was fine. It was only the compiler which saw the problems.
The next day I figured out there is a small detail in my path. Just take a look at directory names casing:
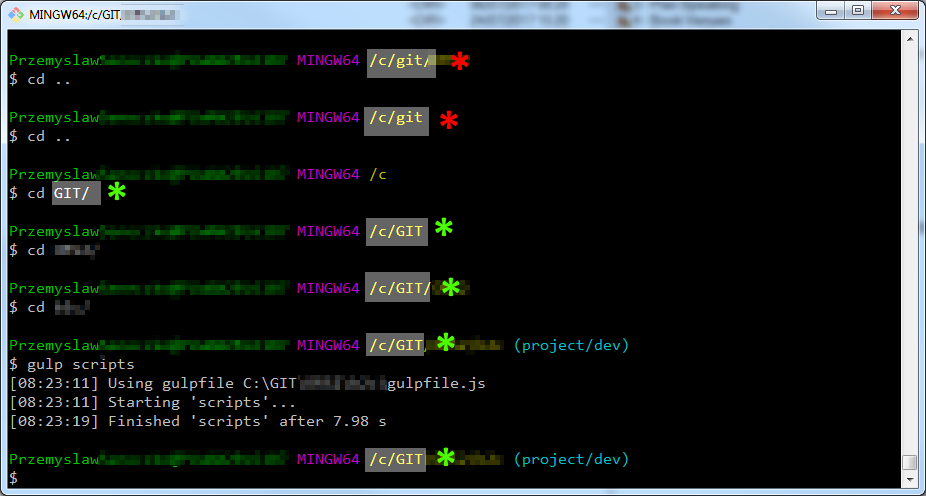
TypeScript compiler ran successfully
After changing the directory using names with proper casing everything was fine. What actually happened was that, I somehow opened the git bash providing the current directory name using lower case letters. It is not that difficult to do that. This is a flaw in the MINGW implementation of bash, I think. It just allows you to change the directory using its name written with whatever case. That is not the problem itself, because cmd.exe allows you to do so as well. The problem is that it then stores the path (probably in PWD environment variable). Some cross-platform tools, which are case sensitive on other platforms, when executed from git bash with mismatched working directory casing may begin to treat such path as separate one, different from the original one. Especially tools which process files using their paths relative to the current directory, like TypeScript compiler for instance.
This can possibly be a wider class of problems and I guess there are other development tools which behave like that when launched from git bash under before mentioned conditions.
In C# interface implementations are not inherited
It may be obvious to some readers, however I was a little bit surprised when I discovered that. Actually, I realized this by looking at a non-trivial class hierarchy in real world application. One can easily think that discussion about inheritance is kind of theoretical area and it primarily appears during job interviews, but it is not true. I will explain real use case and real reasoning behind this hierarchy later in this post, now please take a look at the following program. Generally, the point is that 1) we have to use reference of an interface type and we want more than one specialized implementations of the interface 2) we need to have class B inherit from class A. Without the second requirement it would be obvious: it would be sufficient just to write two separate implementations of IActivity and we are done.
It prints A does activity despite ia variable storing reference to an object of type B and also despite explicitly declaring hiding of base method. It was not clear to me why is it so. It is obvious that the type B has its own implementation, so why is it not run here? To overcome this I initially created base class declared as abstract:
It prints B does activity, but it also is overcomplicated. Then I came up with simpler solution — it turns out we have to explicitly mark class B as implementing IActivity.
It prints B does activity, but it is not perfect. Method hiding is not a good practice. Finally I ended up with more elegant (and the simplest, I guess) solution:
In here we are using virtual and override modifiers to clearly specify an intention of specializing the method. It is better than previous one, because just by looking at class A we are already informed that further specialization is going to occur.
The real usage scenario is that we have an interface representing Entity Framework Core context. We have two distinct implementations: one uses real database and the other uses in-memory database for tests. The latter inherits from the former because what inheritance is all about is copying code. We just want to have the same methods for in-memory implementation like for regular one, but with some slight modifications e.g. in methods executing raw SQL. We also have to use an interface to refer to these objects, because this is how dependency injection containers work.
As you can see, what might seem purely theoretical, actually is used in real world line of business application. Although I have been pretty confident I understand the principles of inheritance in object oriented programming since my undergrad computer science lectures, but as I mentioned, I was surprised discovering that we have to explicitly put : IActivity on class B. The implementation has already been there. Anyway, this example encourages me to be always prepared to verify assumptions I make.
The bookmarks problem
I have been using Mozilla based web browsers since 2003. Back in the days, the application was called Mozilla Suite, then in 2004 the Firefox showed up using the same engine, but with completely new front end. I migrated my profile over the years many times, but I always kept bookmarks. Some of my bookmarks surely remember those early days before Firefox (yet, majority of the oldest are no longer valid, because sites were shut down). The total number of my browser bookmarks gathered over that time is over 1k. And this is `the problem`.
I had several attempts to clean up and organise this huge collection. I have tried to remove dead ones and to group them in folders. I have tried using keywords and descriptions to be able to search more effectively. But with no success. Now I have something about dozen of folders, but I still find myself in trouble when I need to search for particular piece of information. The problem boils down to that: I absolutely remember what the site is about, I am absolutely sure I have it in my collection but I cannot find it because either it has some strange title or words in URL are meaningless (Firefox searches only within titles and urls, because obviously that is all it can do).
I realized I need a tool which is much more powerful when it comes to bookmarks searching. I could not find anything to satisfy my requirements so I implemented it myself. Today I am introducing BookmarksBase which is an open source tool written in C# to solve this issue.
BookmarksBase embraces a concept that may seem ridiculous: why don’t we pull all textual contents from all sites in bookmarks. Do you think it is lots of data? How much it would be? Even if you were to sacrifice a few hundreds of megs in order to be able to search really effectively, isn’t it worth that space?
Well, it turns out it takes much less space than I originally expected and the tool works surprisingly fast, although it is implemented in managed code without any distinguished optimizations. First we have to run separate tool to collect data (BookmarksBase Importer). Downloading + parsing takes maybe a minute or two. Produced index file containing all text from all sites in bookmarks, which I call bookmarksbase.xml in my case is only 12 MiB (over 1000 bookmarks). Then we can run BookmarksBase Search that allows us to perform actual searching within contents/addresses/titles. Surely, when you have bookmarksbase.xml created you can run whatever serves the purpose for you e.g. grep, findstr (in Windows) or any kind of decent text editor that can handle big amounts of text. I crafted XML so that it can be easily readable by human: there is new lines, and the text is preserved in nice column of fixed width (thanks to Lynx — see source for details).
More details and download link are available on GitHub
You are billed for turned off Azure VMs as well
If you are new to Microsoft Azure you will barely guess that. When you shut down your virtual machine, compute hour counter counts just like when it is running and you have to pay for it as well. This “minor” detail is not explained in many official introductory documentation materials I have read. I have realized that only because I am kind of person who likes to re-verify things over and over again and that is why I went to my account’s billing details. I had used my VM just for few days and each day only few hours and after that I saw nearly 200 compute hours in my bill.
Indeed, there are reasonable technical reasons why even powered off machine is billed too. When you create a virtual machine you consume data center resources and they have to remain allocated for you e.g. IP address, CPU cores, storage etc. It does not matter if it is running as this resources still must be reserved and ready for you.
The solution for this problem is to use Azure Powershell to control your virtual machines. The default options of stopping command does also what is called deallocation and then the payment counter stops.
Below I present quick reference of relevant commands.
- You need to “log in” to your Azure account from PowerShell. You do this either with
Import-AzurePublishSettingsFile filenameor withAdd-AzureAccountcommands. Use the former if you would like to use profile settings file downloaded from the portal, and use the latter if you prefer to just type Microsoft account credentials and have the shell store them for you. In both cases credentials are stored inC:\Users\**name**\AppData\Roaming\Windows Azure Powershell. - Use
Get-AzureSubscriptionto list your subscriptions. - Use
Select-AzureSubscription -SubscriptionName **name**to switch the shell to apply following commands to this subscription. - Use
Get-AzureVMto list your virtual machines, their names and their states. - Use
Stop-AzureVM -ServiceName **name** -Name **name**to shut down and deallocate a virtual machine. - Use
Start-AzureVM -ServiceName **name** -Name **name**to power on a virtual machine.
When you close the shell, and open it again you do not have to log in to your Microsoft Account again, but before you are able to control virtual machines you have to select subscription first.
Category: Solutions |
