I have been using Mozilla based web browsers since 2003. Back in the days, the application was called Mozilla Suite, then in 2004 the Firefox showed up using the same engine, but with completely new front end. I migrated my profile over the years many times, but I always kept bookmarks. Some of my bookmarks surely remember those early days before Firefox (yet, majority of the oldest are no longer valid, because sites were shut down). The total number of my browser bookmarks gathered over that time is over 1k. And this is `the problem`.
I had several attempts to clean up and organise this huge collection. I have tried to remove dead ones and to group them in folders. I have tried using keywords and descriptions to be able to search more effectively. But with no success. Now I have something about dozen of folders, but I still find myself in trouble when I need to search for particular piece of information. The problem boils down to that: I absolutely remember what the site is about, I am absolutely sure I have it in my collection but I cannot find it because either it has some strange title or words in URL are meaningless (Firefox searches only within titles and urls, because obviously that is all it can do).
I realized I need a tool which is much more powerful when it comes to bookmarks searching. I could not find anything to satisfy my requirements so I implemented it myself. Today I am introducing BookmarksBase which is an open source tool written in C# to solve this issue.
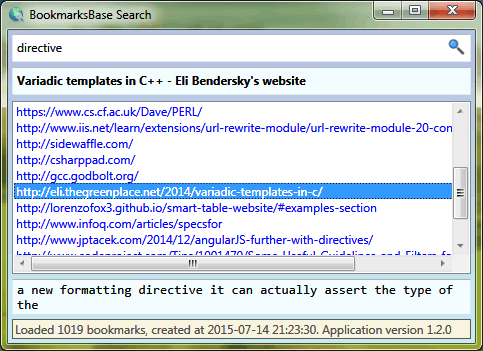
BookmarksBase embraces a concept that may seem ridiculous: why don’t we pull all textual contents from all sites in bookmarks. Do you think it is lots of data? How much it would be? Even if you were to sacrifice a few hundreds of megs in order to be able to search really effectively, isn’t it worth that space?
Well, it turns out it takes much less space than I originally expected and the tool works surprisingly fast, although it is implemented in managed code without any distinguished optimizations. First we have to run separate tool to collect data (BookmarksBase Importer). Downloading + parsing takes maybe a minute or two. Produced index file containing all text from all sites in bookmarks, which I call bookmarksbase.xml in my case is only 12 MiB (over 1000 bookmarks). Then we can run BookmarksBase Search that allows us to perform actual searching within contents/addresses/titles. Surely, when you have bookmarksbase.xml created you can run whatever serves the purpose for you e.g. grep, findstr (in Windows) or any kind of decent text editor that can handle big amounts of text. I crafted XML so that it can be easily readable by human: there is new lines, and the text is preserved in nice column of fixed width (thanks to Lynx — see source for details).
More details and download link are available on GitHub
